

Το νευρωνικό δίκτυο είναι ένας τύπος μοντέλου μηχανικής μάθησης που έχει σχεδιαστεί για να μιμείται τον τρόπο με τον οποίο λειτουργεί ο ανθρώπινος εγκέφαλος, να μαθαίνει και να διορθώνεται μέσα από τα λάθη του.
Η έννοια του μαθηματικού νευρώνα έχει διατυπωθεί ήδη από τη δεκαετία του 1940!
Οι απαρχές των νευρωνικών δικτύων ανάγονται στις πρώτες προσπάθειες που έγιναν την δεκαετία του 1960 1, και την ακόμα παλαιότερη έννοια του μαθηματικού νευρώνα 2, ενός θεωρητικού στοιχείου που προσλαμβάνει σήματα εισόδου και αποφασίζει αν θα ενεργοποιηθεί ή όχι. Στην βάση των εφαρμογών των νευρωνικών δικτύων είναι η έκφραση του νευρώνα ως μαθηματικής συνάρτησης με πολλαπλά ορίσματα εισόδου, η τιμή της οποίας συγκρίνεται με ένα όριο ενεργοποίησης.
Αν η τιμή αυτή περάσει το όριο, ο νευρώνας θα ενεργοποιηθεί και θα μεταδώσει με τη σειρά του ένα σήμα προς όποιον άλλον νευρώνα είναι συνδεδεμένος. Ανάλογα οι πραγματικοί νευρώνες δίνουν ένα μικρό παλμό ηλεκτρικού ρεύματος, όταν δεχτούν αρκετά μεγάλη ενεργοποίηση από το περιβάλλον τους, επηρεάζοντας έτσι τους γειτονικούς τους νευρώνες, ή και πιο απομακρυσμένους μέσω των νευραξόνων.
Οι άλλοι νευρώνες που δέχονται το παραγόμενο σήμα, θα αποφασίσουν και αυτοί με τη σειρά τους αν θα ενεργοποιηθούν ή όχι, λαμβάνοντας υπόψη το σύνολο των αναλόγων νευρώνων με τους οποίους είναι συνδεδεμένος ο καθένας.

Εξού και προκύπτει η έννοια ενός δικτύου από τεχνητούς νευρώνες. Η δομή αυτού του δικτύου, όπως και οι συναρτήσεις των νευρώνων του, είναι που διαφοροποιούν το κάθε νευρωνικό δίκτυο και το κάνουν κατάλληλο για διαφορετικές εργασίες, κατ’ αναλογία με ότι συμβαίνει με τους ανθρώπινους νευρώνες.
Αρχιτεκτονική των νευρωνικών δικτύων
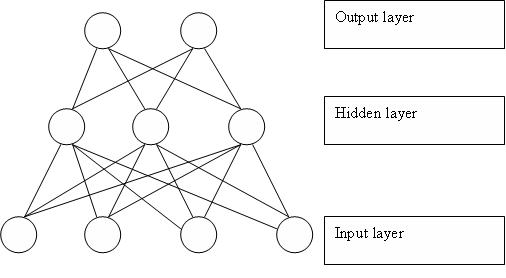
Για την εκτέλεση αντιληπτικών και νοητικών έργων από νευρωνικά δίκτυα, οι νευρώνες κατανέμονται σε διαφορετικά επίπεδα που συγκροτούν μια αρχιτεκτονική.
Τα επίπεδα αυτά στην πιο απλή μορφή δικτύων είναι τρία, δηλαδή η είσοδος, η έξοδος, και το “κρυμμένο” επίπεδο.
Η αναγκαιότητα του κρυφού επιπέδου προκύπτει γιατί τα σύνθετα έργα απαιτούν μία ευελιξία που δεν είναι αποτέλεσμα της ένα-προς-ένα αντιστοίχησης ανάμεσα σε συνδυασμούς των τιμών εισόδου με την απόφαση που λαμβάνεται στο σημείο εξόδου.
Στα κρυφά επίπεδα και στις μεταξύ τους συνδέσεις είναι που συμβαίνει η μάθηση, που μπορεί να γίνει επίσης κατανοητή ως στατιστική γενίκευση με αφετηρία τα δεδομένα που τροφοδοτούμε στο δίκτυο, ώστε αυτό να μπορεί να ανταποκριθεί στη βάση αυτών και προς νέες περιπτώσεις.
Ένα απλουστευτικό παράδειγμα είναι η εκμάθηση του αν ένα ζώο είναι πουλί εφόσον πληροί κάποια χαρακτηριστικά, πχ “έχει φτερά, πετάει, δεν ζεί στο νερό”.
Προφανώς υπάρχουν παραδείγματα όπως η στρουθοκάμηλος ή η κότα, που δεν είναι “στερεοτυπικά” πουλιά.
Τα νευρωνικά δίκτυα επιδεικνύουν επιτυχώς συμπεριφορά που με την τυπική λογική θεωρούνται “παράλογες”, όπως και οι ανθρώπινοι εγκέφαλοι!
Ένα νευρωνικό δίκτυο μπορεί να μάθει να εκτελεί το έργο σωστά, και αν αναλύσουμε τις ενεργοποιήσεις των στοιχείων του κρυφού επιπέδου θα βρούμε ότι έχει αναπτύξει μια χαλαρή διάσταση “πτηνότητας”, χάρις στην οποία πετυχαίνει το έργο, αδιαφορώντας (όπως και οι ανθρώπινοι εγκέφαλοι) για τον αριστοτελικό ορισμό σχετικά με την “ειδοποιό διαφορά” του τί είναι πτηνό. 3
Ένα άλλο παράδειγμα είναι η συμπλήρωση ελλιπών μοτίβων. Πρόκειται για τη δεξιότητα που αξιοποιούμε όταν διαβάζουμε ένα μισοσβησμένο μήνυμα.
Το κρυφό επίπεδο κρατά μία αναπαράσταση των γραμμάτων που είναι ανθεκτική στην απουσία επιμέρους χαρακτηριστικών. Η ενεργοποίηση των υπολοίπων χαρακτηριστικών είναι αρκετή για να ενεργοποιηθεί έμμεσα και το στοιχείο που λείπει. 4
Νευρωνικό δίκτυο ως συστοιχία μοντέλων παλινδρόμησης
Οι ακριβείς υπολογισμοί που λαμβάνουν χώρα στα κρυφά στρώματα είναι αρκετά πιο σύνθετοι στην πραγματικότητα 5, αλλά θα παρέχουμε εδώ μια αναλογία που βοηθάει να γίνει αντιληπτό στη γενική του μορφή το τι ακριβώς κάνει ένα νευρωνικό δίκτυο. 6
Ας πάρουμε για παράδειγμα ένα πιο παραδοσιακό μοντέλο στατιστικών προβλέψεων, αυτό της εξίσωσης παλινδρόμησης που προβλέπει μια δυαδική μεταβλητή, για παράδειγμα αν ένας μαθητής θα περάσει τη βάση στην τελική εξέταση του μαθήματος.
Η εξίσωση παλινδρόμησης εκφράζει την πιθανότητα να περάσει ένας φοιτητής το μάθημα, λαμβάνοντας υπόψη ορισμένους προβλεπτικούς παράγοντες!
Είναι γνωστό ότι η εξίσωση παλινδρόμησης εκφράζει την πιθανότητα να συμβεί αυτό ως συνάρτηση κάποιων άλλων παραγόντων που ονομάζονται προβλεπτικές μεταβλητές, όπως πχ το κοινωνικοοικονομικό επίπεδο, οι παράγοντες ψυχοκοινωνικού ρίσκου στο περιβάλλον του μαθητή, οι επιδόσεις του στα ενδιάμεσα διαγωνίσματα, οι βαθμοί σε σχετικά μαθήματα κλπ. Στην περίπτωση αυτή προϋποτίθεται ο σχετικός μετασχηματισμός για να εκφραστεί το προβλεπόμενο αποτέλεσμα σαν λόγος πιθανοτήτων (το κατά πόσον είναι πιθανότερο να περνάει όλα τα μαθήματα σε σχέση με το να μην περνάει, όπως όταν λέμε ότι κάτι είναι 3 φορές πιθανότερο). 7
Το σύνολο των παραδειγμάτων εκπαίδευσης περιλαμβάνει γνωστές τιμές σε όλες τις προβλεπτικές μεταβλητές, και γνωστή “έκβαση”, δηλαδή οι πραγματικές μετρήσεις (εδώ, το αν κάθε μαθητής περνάει ή δεν περνάει τη βάση στο μάθημα), δίνονται στην εκπαίδευση.
Γενικά οι μέθοδοι παλινδρόμησης (πχ η μέθοδος που ελαχιστοποιεί τις διαφορές των προβλεπόμενων από τις πραγματικές τιμές) είναι καλές στο να βρίσκουν συντελεστές με τους οποίους σταθμίζουν τους προβλεπτικούς παράγοντες και τους προσθέτουν τελικά μεταξύ τους. Πρόκειται όπως λέμε για γραμμικούς συνδυασμούς των αρχικών τιμών, και φτάνουν εκεί υπολογίζοντας τους συντελεστές για τους οποίους η απόκλιση των τιμών που εκτιμά το μοντέλο σε σχέση με τις πραγματικές μετρήσεις ή ο αριθμός των εσφαλμένων εκτιμήσεων για ένα μεγάλο αριθμό παραδειγμάτων εκπαίδευσης, ελαχιστοποιείται.
Ένα νευρωνικό δίκτυο μπορεί να θεωρηθεί και ως συστοιχία από τέτοια μοντέλα λογαριθμικής παλινδρόμησης, όπου κάθε νευρώνας χρησιμοποιεί ως προβλεπτικές μεταβλητές τους άλλους νευρώνες, ενώ το κατηγορικό αποτέλεσμα (περνάει ή δεν περνάει) είναι το αν ο κάθε νευρώνας θα ενεργοποιηθεί ή όχι. Μέσα από διαδοχικές επαναλήψεις εκπαίδευσης, το δίκτυο διορθώνει βαθμιαία την εσωτερική του αναπαράσταση, αλλάζοντας λίγο-λίγο τις παραμέτρους των νευρώνων του, μέχρι να πετύχει ελαχιστοποίηση του σφάλματος πρόβλεψης. Με άλλα λόγια οι προβλεπόμενες από αυτό τιμές να είναι (με ένα βαθμό ανοχής) όσο το δυνατόν κοντά στις πραγματικές, γνωστές, τιμές. Τελικά το εκπαιδευμένο μοντέλο θα μάθει να προβλέπει σωστά και περιπτώσεις που δεν έχει δεί, στο βαθμό που σφαιρικά οι νέες περιπτώσεις δεν διαφέρουν δραστικά, ως πρός όλες τις μεταβλητές που τις περιγράφουν, από εκείνες τις περιπτώσεις πάνω στις οποίες έχει εκπαιδευτεί.
Έτσι γίνεται αντιληπτό το πλήθος των προβλεπτικών μεταβλητών που μπορούν να τύχουν ταυτόχρονης επεξεργασίας σε διαδοχικές φάσεις. Με μία κρίσιμη διαφορά όμως: την ικανότητα των νευρωνικών δικτύων να μαθαίνουν σύνθετες μαθηματικές σχέσεις, οι οποίες δεν εξαντλούνται στην προσθαφαίρεση συντελεστών (είναι μη γραμμικές, όπως για παράδειγμα οι εκθετικές σχέσεις, οι οποίες είναι καμπυλόγραμμες).
Επισκόπηση των βασικών αρχών της επεξεργασίας φυσικής γλώσσας
Η επεξεργασία φυσικής γλώσσας είναι μια από τις παλαιότερες και διαρκέστερες προκλήσεις της επιστήμης υπολογιστών, που έχει προσεγγιστεί με διαφορετικά πλαίσια θεωρητικών και μεθοδολογικών αρχών εδώ και έξι τουλάχιστον δεκαετίες. 8
Η επεξεργασία φυσικού λόγου, δηλαδή η κατανόηση των ανθρωπίνων γλωσσών από τους υπολογιστές είναι μία από τις παλαιότερες προκλήσεις της επιστήμης υπολογιστών!
Για την κατανόηση της φυσικής γλώσσας από υπολογιστές ακολουθούνται διάφορα στάδια προεπεξεργασίας, που περιλαμβάνουν το καθαρισμό του κειμένου, τον κατατεμαχισμό του σε μονάδες (tokens), την αναγνώριση μέρους του λόγου (ρήμα, ουσιαστικό, κλπ), την αναγνώριση επώνυμων οντοτήτων (ο Δήμος Αθηναίων, η Ευρωπαϊκή Επιτροπή, κλπ), και άλλα.
Άλλες μορφές προεπεξεργασίας περιλαμβάνουν την ανάλυση του κειμένου σε σημασιολογικές συνιστώσες, την ανάλυση της συντακτικής δομής κλπ, που είτε βασίζονται σε στατιστικές ιδιότητες του κειμένου και τη θεωρία πιθανοτήτων, είτε (και) σε καθιερωμένες θεωρίες γλωσσολογίας.
Η επανάσταση την οποία τώρα παρακολουθούμε να εκτυλίσσεται είναι η εκτεταμένη αξιοποίηση των νευρωνικών δικτύων στα “μεγάλα γλωσσικά μοντέλα”.
Τα αναδρομικά νευρωνικά δίκτυα λαμβάνουν υπόψη όχι μόνο τις τρέχουσες τιμές εισόδου τους, αλλά και την προηγούμενη εσωτερική τους κατάσταση. Επιδεικνύουν έτσι ένα είδος βραχυπρόθεσμης μνήμης!
Πρόγονος των σημερινών εξελίξεων στη μηχανική μάθηση είναι τα μοντέλα Μακροπρόθεσμης-Βραχυπρόθεσμης Μνήμης και τα Αναδρομικά Νευρωνικά Δίκτυα, 9 η καινοτομία των οποίων ήταν η ανατροφοδότηση του κρυφού επιπέδου ανάμεσα σε διαδοχικά χρονικά σημεία της εκπαίδευσης, με τρόπο που τα στοιχεία του κρυφού επιπέδου λαμβάνουν υπόψη όχι μόνο τις τιμές εισόδου αλλά και τα σήματα που προέκυψαν από την προηγούμενη κατάστασή τους.
Με τον τρόπο αυτό οι προηγούμενες ενεργοποιήσεις των νευρώνων λαμβάνονται υπόψη στις επόμενες αποφάσεις των ίδιων νευρώνων, έχοντας έτσι ένα ανάλογο βραχυπρόθεσμης μνήμης. Παράλληλα, προστίθενται νευρώνες που μαθαίνουν να αποφασίζουν πότε η προηγούμενη μνήμη θα πρέπει να αγνοηθεί και πότε να ληφθεί υπόψη, δίνοντας ακόμη μεγαλύτερο ενδιαφέρον και πολυπλοκότητα στην αρχιτεκτονική.
Αυτό το τέχνασμα μπορούσε βέβαια να επεκταθεί σε περισσότερα χρονικά σημεία, αλλά το υπολογιστικό κόστος σε αυτήν την περίπτωση αυξάνεται σε σημείο απαγορευτικό για μοντέλα με χιλιάδες ή εκατομμύρια κρυφά στοιχεία όπως αυτά που απαιτούνται για τη γλωσσική επεξεργασία.
Μέχρι που τα εργαστήρια της Google δημοσίευσαν ένα άρθρο με τίτλο “Το μόνο που χρειάζεστε είναι η προσοχή”. 10
Μηχανισμοί προσοχής: Από την αυτοκωδικοποίηση στην μετάφραση
Για να το καταλάβουμε αυτό, ας δούμε πρώτα πως λειτουργεί ένα νευρωνικό δίκτυο που πρέπει να επιστρέψει την ίδια του την είσοδο (έργο αυτοκωδικοποίησης).
Για να το πετύχει αυτό πρέπει να συμπιέσει την πληροφορία της εισόδου σε μία εσωτερική βαθύτερη αναπαράσταση (ως προς αυτό θεωρείται ομόλογο με διάφορες μορφές ανάλυσης σε ατομικές ή κύριες συνιστώσες). Αυτό το παράδειγμα πρέπει να συνεξεταστεί με όσα αναφέρθηκαν παραπάνω με το απλουστευτικό παράδειγμα της “πτηνότητας”, αλλά δεν θα επεκταθούμε εδώ.11 Θα περιοριστούμε μόνο στη διαπίστωση ότι ένα δίκτυο που κάνει αυτοκωδικοποίηση αναγκάζεται να αναπαραστήσει με μικρότερο αριθμό νευρώνων τις τιμές που έχει στην είσοδο και να την αποκαταστήσει στους νευρώνες εξόδου. Ως προς αυτό συνιστά “μείωση των διαστάσεων” ή “συμπίεση” και για αυτό θεωρείται ότι ομοιάζει με μία ανάλυση σε συνιστώσες του αρχικού πίνακα με τις τιμές εισόδου, αν και ο τρόπος με τον οποίο φτάνει σε αυτό το αποτέλεσμα είναι διαφορετικός (εν προκειμένω η οπισθοδιάδοση του σφάλματος).
Τα μοντέλα αυτού του είδους που χρησιμοποιούνται για παράδειγμα σε αυτόματη μετάφραση, παρακολουθούν το κείμενο λέξη-προς-λέξη. Αλλά υπάρχει ένα επίπεδο που κωδικοποιεί την βαθύτερη αναπαράσταση της γλώσσας προέλευσης, που συνδέεται με την ομόλογή της βαθύτερη αναπαράσταση της γλώσσας στόχου, από όπου προκύπτει και η επιφανειακή δομή της γλώσσας στόχου, δηλαδή το μετεφρασμένο κείμενο. Αυτό ονομάζεται υπόδειγμα κωδικοποίησης-αποκωδικοποίησης διότι το κρυφό επίπεδο της γλώσσας προέλευσης κωδικοποιεί την εισροή ενώ το κρυφό επίπεδο της γλώσσας στόχου την αποκωδικοποιεί.
Με την αναδρομική αρχιτεκτονική τα συμφραζόμενα κωδικοποιούνται στην ενεργοποίηση του κρυφού επιπέδου της πρώτης γλώσσας, αλλά αυτό εισάγει δυσκολίες όταν τα συμφραζόμενα είναι ιδιαίτερα απομακρυσμένα μεταξύ τους, όπως είναι γνωστό ότι συμβαίνει στη φυσική γλώσσα με τις απομακρυσμένες σχέσεις μεταξύ λέξεων στο κείμενο. Σε αυτή την περίπτωση η βραχύχρονη μνήμη δεν αρκεί για να εντοπίσει λεξικές σχέσεις με αυτές τις απομακρυσμένες λέξεις, ενώ αν είναι πολύ μακριά, τότε το δίκτυο γίνεται πλέον πολύ δύσκολο να εκπαιδευτεί.
Ο μηχανισμός προσοχής εισάγεται σε αυτό το σημείο για να δώσει διαφορετικό βάρος σε διαφορετικά χρονικά σημεία που ανατροφοδοτούν το κρυφό επίπεδο. Αυτά μπορεί να είναι είτε στη γειτονιά της τρέχουσας λέξης ή στον ορίζοντα ενός αποσπάσματος κειμένου. Έτσι η μνήμη εργασίας του δικτύου γίνεται πιο επιλεκτική, και άρα πιο αποτελεσματική.
Με την εισαγωγή του μηχανισμού προσοχής, τα νευρωνικά δίκτυα μπορούν να εκπαιδεύονται σε σύνθετα έργα κωδικοποίησης-αποκωδικοποίησης, χωρίς να καταφεύγουν σε αναδρομή!
Σε κάθε στάδιο της επεξεργασίας, διαφορετικά στοιχεία της εισροής θεωρούνται ως σχετικότερα με την τρέχουσα επεξεργασία, και έτσι λέμε ότι “εστιάζεται η προσοχή” του μοντέλου. Αλλά οι υπολογισμοί αυτοί έχουν εκ φύσεως τη μορφή της χρονικής ακολουθίας, και δεν μπορούν να αξιοποιηθούν για παράλληλη επεξεργασία.
Οι σύγχρονες εξελίξεις απαλείφουν το κομμάτι της αναδρομής και εισάγουν την έννοια της εαυτό-προσοχής του μοντέλου. Με αυτές τις τεχνικές ένα μοντέλο μπορεί να εκπαιδευτεί απευθείας σε ζεύγη προτάσεων από τη γλώσσα προέλευσης στη γλώσσα στόχο.
Και αυτό όμως απαιτεί μεγάλο όγκο δεδομένων εκπαίδευσης, τα οποία μπορεί να μην είναι διαθέσιμα. Για αυτό επιστρατεύτηκε η τεχνική της “μεταφοράς μάθησης” (transfer learning), που αναπτύχθηκε ιδιαίτερα κατά την τελευταία δεκαετία στον τομέα της μηχανικής όρασης.12
Μεταφορά μάθησης και βαθμονόμηση μοντέλων
Στην τεχνική αυτή, ένα μοντέλο έχει ήδη εκπαιδευτεί σε δεδομένα μεγάλου όγκου, και έχει ήδη διαμορφωμένα “βάρη” στα κρυφά του επίπεδα. Καθίσταται έτσι “προεκπαιδευμένο”. Με βάση όσα ήδη είπαμε, αυτό σημαίνει ότι έχει κατακτήσει “βαθύτερη γνώση” που αφορά σε ένα συγκεκριμένο τομέα, στον οποίο έχει εκπαιδευτεί. Στο παράδειγμα της μηχανικής όρασης ας πούμε μπορεί ένα μοντέλο να έχει προεκπαιδευτεί στον εντοπισμό βασικών οπτικών χαρακτηριστικών όπως των περιγραμμάτων, των βασικών μοτίβων και του χρώματος των αντικειμένων.
Μπορεί τότε να χρησιμοποιηθεί για να εκπαιδευτεί σε ένα νέο έργο, στο οποίο η γνώση αυτή είναι προαπαιτούμενο, πχ την ανάγνωση πινακίδων κυκλοφορίας.
Έτσι εξασφαλίζεται ένα μοντέλο το οποίο είναι καλά εκπαιδευμένο και με πιό οικονομικό τρόπο, αφού η ακριβή εκπαίδευση στα βασικά χαρακτηριστικά του κάθε προς οπτική αναγνώριση αντικειμένου επαναχρησιμοποιείται.
Αν και καθιερωμένη στην μηχανική όραση, η μεταφορά μάθησης δεν είχε μέχρι πρόσφατα εφαρμοστεί ευρέως στην φυσική γλώσσα, με αποτέλεσμα να μην έχουμε ανάλογη πρόοδο στα έργα επεξεργασίας φυσικού λόγου. 13
Σε αυτό το σημείο έρχεται η μεθοδολογία της OpenAI που εισήγαγε ένα πρωτόκολο που οδηγεί σε μοντέλα με πολύ καλές επιδόσεις σε έργα επεξεργασίας φυσικού λόγου.14
Με την μέθοδο της βαθμονόμησης, το μοντέλο μπορεί να αποκτήσει γενική σημασιολογική γνώση από μεγάλα σώματα κειμένων που δεν έχουν κατηγοριοποιηθεί από άνθρωπο, και έτσι με μικρότερο κόστος να “προετοιμαστεί” για συγκεκριμένα έργα!
Η μεθοδολογία αυτή συνίσταται στα εξής βήματα:
- Κατά την προεκπαίδευση (μοντελοποίηση γλώσσας) το μοντέλο εκπαιδεύεται χωρίς ετικέτες, σε κείμενο που μπορεί να ανακτηθεί ελεύθερα, πχ την αγγλική Wikipedia ή το Project Gutenberg. Αυτά τα σώματα κειμένων μπορούν να δοθούν προς εκπαίδευση χωρίς άλλη ανθρώπινη επισημείωση, ή κατηγοριοποίηση.
Η εκπαίδευση έχει τη μορφή “προβλέπω την επόμενη λέξη σε αυτήν την ακολουθία” η οποία μπορεί να φαίνεται απλοϊκή, αλλά η επίδοση σε αυτό το έργο εξαρτάται από την γνώση συμφραζομένων που πρέπει να εσωτερικεύσει το μοντέλο.
Κάποιοι ερευνητές βρήκαν ότι τα μοτίβα ενεργοποίησης των κρυφών στοιχείων ενός σύγχρονου γλωσσικού μοντέλου είναι αντίστοιχα με τις καταγραφές της εγκεφαλικής δρατηριότητας ανθρώπων που επιδίδονται στο ίδιο έργο. 15
- Το προεκπαιδευμένο μοντέλο εκτελεί το ίδιο έργο αλλά σε ένα εξειδικευμένο σύνολο κειμένων, πχ κριτικές ταινιών από το Internet Movie Database. Αποκτά έτσι “κατά τομέα εξειδικευμένη γνώση”.
- Τέλος, προστίθεται ένα ακόμα επίπεδο ταξινόμησης κειμένου, στο οποίο εκπαιδεύεται με ένα σαφώς μικρότερο όγκο δεδομένων, για παράδειγμα την απόφαση για το αν μια συγκεκριμένη κριτική είναι θετική ή αρνητική. Αυτό λέγεται βαθμονόμηση του μοντέλου σε ένα συγκεκριμένο έργο (fine-tuning).
Τα έργα κλειδιά στα οποία εφαρμόζονται πλέον αυτές οι τεχνικές είναι
- η αναγνώριση επώνυμων οντοτήτων,
- η ταξινόμηση κειμένου,
- η αυτόματη μετάφραση,
- η παραγωγή κειμένου,
- η απάντηση σε ανοιχτές ερωτήσεις,
- τα chatbot κα.
Οι εξελίξεις στον χώρο των μεγάλων γλωσσικών μοντέλων, που προχωρούν τόσο ραγδαία που απαιτούν συνεχή παρακολούθηση τόσο των τεχνολογικών ιστοτόπων όσο και της επιστημονικής αρθρογραφίας. Για το σκοπό αυτό ακολουθήστε τις αναρτήσεις μας, καθώς σύντομα θα διοργανωθούν εργαστήρια και ομάδες για την πρακτική εξάσκηση σε υποδειγματικές εφαρμογές των νευρωνικών δικτύων και των γλωσσικών μοντέλων.

Επόμενα βήματα
Τα επόμενα βήματα για όποιο άτομο θέλει να ασχοληθεί με τα μεγάλα γλωσσικά μοντέλα είναι η εξοικείωση με την πλατφόρμα-αποθετήριο Hugging Face, και την ανάγνωση των κατατοπιστικών καρτών που συνοδεύουν τα εκεί αναρτημένα μοντέλα και σύνολα δεδομένων.
Η μελέτη των σχετικών βιβλίων και άρθρων.
Η παρακολούθηση των εξελίξεων ανά εβδομάδα σε ιστότοπους τεχνολογίας.
Η εγκατάσταση και ο πειραματισμός με τη βιβλιοθήκη transformers της Python.
Addendum (13 Απριλίου):
Ορισμένες διευκρινήσεις σε ερωτήσεις που έχουν τεθεί σε αυτό το κείμενο
- Για να εκπαιδευτεί ένα μεγάλο γλωσσικό μοντέλο στα ελληνικά, θα πρέπει να εκπαιδευτεί σε σώμα κειμένων της ελληνικής γλώσσας που αντανακλά διαφορετικές εποχές και εύρος από γλωσσικές ποικιλίες, ώστε να αποκτήσει ευελιξία σε οποιοδήποτε κειμενικό είδος ή συγκεκριμένη εφαρμογή.
- Για συγκεκριμένες εργασίες, όπως πχ απάντηση ερωτήσεων, ταξινόμηση κειμένου, ή δημιουργία chat bot θα πρέπει επιπλέον να περάσει από την ίδια διαδικασία με το εκάστοτε είδος, πχ νομικά ή ιατρικά κείμενα. Ο λόγος είναι το ότι το μοντέλο πρέπει να μάθει τις ιδιαίτερες ορολογίες του πεδίου και το πως συνδέονται μεταξύ τους, αξιοποιώντας όμως την γλωσσική του ικανότητα στα ελληνικά που συζητήθηκε στο προηγούμενο βήμα.
- Τέλος, για να επιτελέσει εργασία σε συγκεκριμένο πεδίο, πχ εξαγωγή απαντήσεων από ένα σώμα κειμένων, θα πρέπει να εκπαιδευτεί και να εμπλουτιστεί με δεδομένα εκπαίδευσης, πχ εδώ προσεκτικά επιμελημένα ζεύγη ερωτήσεων-απαντήσεων στο συγκεκριμένο πεδίο. Οι διαδικασίες αυτές αξιολογούνται με συγκεκριμένες μετρικές, και για υψηλής σημασίας εφαρμογές, (πχ θα το αφήναμε να δίνει ιατρικές συμβουλές;), θα πρέπει τα αποτελέσματα να επιτηρούνται στενά και να επαναξιολογούνται από ανθρώπους.
Παρακολουθήστε τις επόμενες δημοσιεύσεις και δραστηριότητές μας σχετικά με τα μοντέλα μηχανικής μάθησης, και υποβάλλετε όποια ερώτηση έχετε στο τμήμα σχολίων, ώστε να μπορούν να τοποθετηθούν και άλλα άτομα, και να οικοδομηθεί συνολικά η γνώση μας για το θέμα!
- Minsky, M. L., & Papert, S. A. (1969). Perceptrons: An introduction to computational geometry. MIT Press.↩︎
- McCulloch, W. S., & Pitts, W. (1943). A logical calculus of the ideas immanent in nervous activity. Bulletin of Mathematical Biophysics, 5(4), 115-133.↩︎
- Rumelhart, D. E., McClelland, J. L., & the PDP Research Group. (1986). Parallel distributed processing: Explorations in the microstructure of cognition (Vol. 1). MIT Press.↩︎
- O’Reilly, R. C., & Munakata, Y. (2000). Computational explorations in cognitive neuroscience: Understanding the mind by simulating the brain. MIT Press.↩︎
- Rumelhart, D. E., Hinton, G. E., & Williams, R. J. (1986). Learning representations by back-propagating errors. Nature, 323(6088), 533-536.↩︎
- Garson G. D. (1998). Neural networks : an introductory guide for social scientists. Sage Publications. Retrieved April 6 2023 from https://public.ebookcentral.proquest.com/choice/publicfullrecord.aspx?p=537802.↩︎
- Λόγω του μετασχηματισμού αυτού είναι που μιλάμε για λογαριθμική παλινδρόμηση.↩︎
- Jurafsky, D., & Martin, J. H. (2019). Speech and language processing (3rd ed.). Pearson.↩︎
- Chung, J., Gulcehre, C., Cho, K., & Bengio, Y. (2014). Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv:1412.3555.↩︎
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008).↩︎
- Hinton, G. E., & Salakhutdinov, R. R. (2006). Reducing the dimensionality of data with neural networks. Science, 313(5786), 504-507.↩︎
- Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). ImageNet classification with deep convolutional neural networks. In Advances in neural information processing systems (pp. 1097-1105).↩︎
- Do, C. B., & Ng, A. Y. (2005). Transfer learning for text classification. Advances in neural information processing systems, 18.↩︎
- Howard, J., & Ruder, S. (2018). Universal language model fine-tuning for text classification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 328-339).↩︎
- Caucheteux, C., Gramfort, A. & King, JR. Evidence of a predictive coding hierarchy in the human brain listening to speech. Nat Hum Behav 7, 430–441 (2023). https://doi.org/10.1038/s41562-022-01516-2↩︎
Δείτε για ενημέρωση το https://cedille.ai (German, French) και το https://coteries.com/en/blog/cedille-ai-launches-german-language-model/ .